Tests Should Pull Their Weight
Test-driven development has been around for a long time now, with many vocal advocates, and yet few people or organizations really seem to adhere to it. Why is that? If I had to hazard a guess, I’d say it’s because most developers’ experience with tests is that they’re usually not worth it. They take a long time to write, and they take even longer to maintain, and the number of potential important issues that they catch (and which wouldn’t be caught by other processes) is actually pretty small.
This viewpoint is rational. While the benefits of tests are frequently discussed, their cost often seems overlooked. But it constitutes a significant portion of the cost-benefit analysis that developers make. Many developers feel this cost intuitively: the cost of needing to write fifty lines to set up a single test case, or of needing to update twenty tests whenever I change the parameters to a function, or of CI taking half an hour every time I push a commit, or of spending more time in code review understanding the tests than I take understanding the implementation. We need to recognize this cost, because it’s very real.
The benefits of tests are well established; I think developers would write more tests if the costs could be reduced. So how do we do that?
Making Less Expensive Tests
While most developers don’t follow TDD, many do. Some swear by it. How do they have such a different experience from the majority?
The key difference, I think, is how much time each group spends on their tests. Paradoxically, the best test-writers spend the least amount of time writing and updating tests. They’re able to do this because they write better tests. They craft their tests in a way that minimizes their costs while maximizing their benefits.
Not all tests have an equal cost. The cost of each test can theoretically be measured by how much cumulative time the test takes from developers: time to write it initially, time to read it in code review, time to update it and review it again whenever that may need to happen in the future, time to understand why a change causes the test to fail, and the overall time it takes for the test to run. Four out of five of those are directly related to the complexity of the test code — short and simple test cases are less costly than long and complicated ones.
Tests also don’t provide equal benefits. The benefit of a test could hypothetically be measured by how much time it saves for developers, but this is much harder to even theoretically put a number to, because it’s based on a counter-factual of, “what if we didn’t have this test?” To get a rough sense of it, though, it’s enough to ask: “What potential issues would this test catch? How big of a problem would those be? How likely would they be to be introduced? How likely would they be to be caught by other tests or processes that we have?” The most beneficial tests are those that catch issues that would be severe, or that are very easy to accidentally introduce, or that would be very unlikely to be caught by other processes.
For the best tests, we want to minimize the cost of each test, while maximizing their benefit. Therefore, tests that are long and complicated are only justified if the issues they catch are very important. Tests that test for harmless or unlikely issues are only justified if they are very short and simple. In short, the policy to follow is that tests should pull their weight.
I’m still learning how to improve my tests to allow more of them to pull their weight, but here are some of the basic principles I’ve been starting with.
Test What You Really Care About
I worked in a micro service setup recently where many services depended on other services. In tests, it was common to mock out a service’s dependencies, so that you were testing the single service “in isolation.” The thing is, though, “in isolation” doesn’t automatically make a testing setup good. In our case, our tests often passed because they successfully confirmed that the service made the expected method calls to its dependencies. But we would still encounter issues with the code in production, generally when dependencies changed in a way that no longer matched assumptions we had about their behavior. Tests didn’t catch these issues because they weren’t testing the real method calls of the dependencies.
In fact, I can’t recall these tests ever catching an important issue. That means they weren’t useful, and they certainly weren’t pulling their weight. And the main reason for that is that they weren’t testing what we actually cared about. What was being tested was, “this endpoint calls this other service.” But what we actually cared about was, “this endpoint does the right things in the system.”
I can think of two options to make tests like this more useful: either actually call the real service that you depend on, or else abstract away the important logic to a method or class that doesn’t have any dependencies at all that you need to mock. For me, mocks and spies and things like that are code smells for tests, because they don’t represent how the code will actually behave. They often give rise to useless tests like these. The only legitimate cases I’ve found for mocks are for when an abstraction really does allow the client to pass in their own, completely arbitrary code (eg. for a callback), or maybe sometimes to make a dependency deterministic that otherwise wouldn’t be. 1
Test Abstractions, Not Implementations
Well then, how do you define what you “actually care about” that you should be testing? Generally, you can answer this question by looking to the core abstractions in the code. Whatever these are, “what you actually care about” is that when someone goes to use these abstractions, they behave as expected.
To find what these are for your project, you can use the rule of thumb that they’re the things that you can bring up in conversation with coworkers, and assume that they have the same high-level sense as you for how it’s supposed to behave. They may be services that have a clear contract spelled out; or general-purpose utilities that are widely used; or you could even look to the UI itself, which may have pages or sections or buttons whose expected behavior can be described even by non-technical people.
While languages have their own ways of defining abstractions through interfaces or function signatures, the more important part of an abstraction is the general sense of how someone can expect it to behave. This is something that can’t generally be captured in code, so normally it can only be explained in plain English in a comment or other form of documentation.
The best tests respect the boundaries of the abstractions, testing how they appear to behave from the outside, and not focusing on internal implementation details. Good tests generally follow directly from the documentation of the abstraction. Every promise made in the documentation should be verified by one or more tests. And on the flip side, there’s no need to have a test for behavior that isn’t promised or implied by the documentation. When done this way, tests can also serve as examples for how to use the abstraction, which can be even more useful than the documentation itself.
As engineers, we’re usually thinking about the implementation. But the more your tests are tied to implementation details, the more time you’re going to have to spend updating them in the future when the implementation changes. As such, it’s better to think of your abstractions as black boxes. They promise that they’ll do something. Your tests verify those promises, and they should be able to do that purely by checking what’s externally visible. This leads to much more useful tests that don’t need to change as often.
In my experience, as I’ve tried to follow this rule more, I’ve found myself incentivized to make simpler abstractions, because then the tests become easier to write. As an example, I recently wrote a GraphQL engine in Java, which probably took a couple thousand lines of code. But when I invested early on in writing tests for it, I moved to a simpler abstraction for the engine than what I’d made initially: the main class just has a constructor that gets passed objects that define the GraphQL schema, and then it has a single method called execute() that takes in a GraphQL query and returns a response.
Testing then became very easy: I created a fake schema, and then each test just called execute() with different types of queries and verified the response. It was easy to write tests, so I wrote a lot of them. They gave me confidence with each change that I hadn’t broken anything. A few times I even made large-scale refactors of the implementation that touched nearly every file, but I didn’t have to change a single existing test, because the externally visible behavior hadn’t changed. Aligning the tests with the core abstractions made the tests far less costly, and development became much easier.
Don’t Write Many Tests Until You’ve Settled on the Abstractions
My focus on TDD earlier in this article may have implied that it’s the ultimate procedure for writing tests, but I don’t think you should just blindly follow it. It’s more important keep in mind the goals of good testing, and work toward those goals, whether through TDD or otherwise. For me, there’s one specific case where I disagree with TDD’s prescription to always start by writing tests before writing code, and that’s when you’re in the early stages of developing a new abstraction.
TDD is easy enough to follow when you’re working with an existing part of the codebase. Any change you make to existing abstractions must fall into one of three categories: a refactor; a change to the abstraction; or fixing a bug where the abstraction didn’t do what it promised. Refactors don’t need new tests; the existing ones verify that nothing broke. For the other two kinds of changes, since the abstraction under test already exists, it should be easy enough to add a new test for each change by just following the structure of existing tests. At first the test will fail, and then you can go in and write code and get it working.
But things are different when you’re writing a new abstraction. This is because there will almost always be a period of time during which you’re still figuring out what you want the abstraction to even be. This can be called the exploration phase, and it’s a period where you’re largely experimenting, and want to be able to just make small changes and quickly be able to see results. 2
This is an essential phase for good software design, since it allows you to find the best choice among many options, rather than being stuck with the first idea you have. It’s good and expected for the abstraction to change in this phase as you play with it and start to build it out. But if you write many tests for your first iteration of the abstraction, then you’ll need to update all of them whenever you decide to change it. This will either slow you down or, worse, discourage you from updating the abstraction at all.
Of course, that doesn’t mean you forgo testing altogether (otherwise how do you verify if your experiments are working?), but often testing manually is easiest is this phase. I’ll often set up a very simple test, (maybe even without any assertions, just to give me an entry point to call the code), which I then step through with a debugger to manually explore how it runs and verify my understanding.
In my experience, the best time to build out comprehensive testing is when you’ve settled on the abstraction. The abstraction doesn’t necessarily need to be perfect or completely finished, but you’re no longer expecting major changes to its structure. At this point, you’ve left the exploration phase and are no longer actively changing the abstraction. It’s not always obvious when exactly you’ve crossed that line, but it’s always before the new abstraction has started to be used in production. If you follow a continuous delivery cycle, this means a good rule of thumb is that comprehensive tests should be added before your change is merged into the production branch.
Again, this suggestion only applies to new abstractions. For existing, settled abstractions, TDD works great as-is.
Establish a Testing Pyramid
In an ideal world, if tests could be run and written instantly, the best kinds of tests would be those that run the entire system from end to end, testing every variation and edge case you could think of. Unfortunately, though, in the real world, this isn’t practical. Tests of an entire system take a long time to write and to run and to update later. You should certainly have some tests like that, perhaps for your most important workflows, but if you have too many then developers will be slowed by them, enough to outweigh the diminishing returns of confidence they would provide.
This problem gave rise to the idea of the test pyramid. This is the recommendation that you should have a few different layers of tests, which test different levels of the system. At the bottom are the unit tests, which provide a foundation of confidence in the code. As you go up each layer, larger portions of the system are tested together, but the number of tests goes down as the pyramid narrows, to account for the larger time and maintenance burden these tests impose.
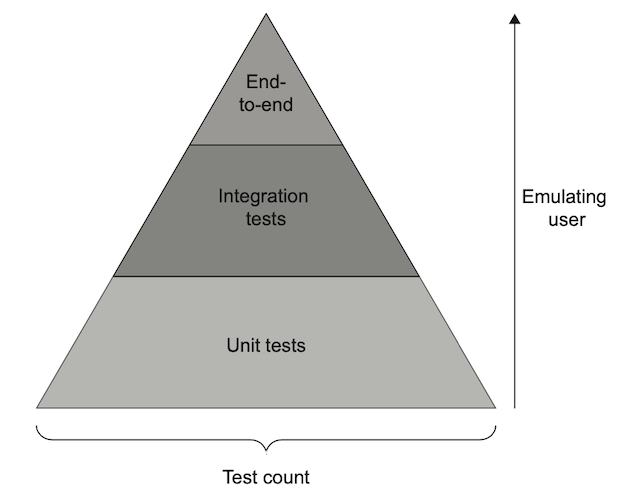
Each layer tests something different. The unit tests should each be small, but together should be very comprehensive, verifying every piece of behavior promised by each of your core abstractions, and testing all of the different edge cases that they could face. Because those edge cases and variations are all tested at this layer, they don’t all need to be tested again at all the higher layers; that would just be redundant. Instead, the higher layers exist primarily to verify that the different pieces of the system are coordinating together properly — because that’s the one thing that unit tests alone can’t verify.
You don’t need to have three layers, or the same layers in your pyramid; different organizations will arrange their pyramids differently. Unit tests are always at the bottom, and some kind of end-to-end tests that validate the whole system should be at the top. The layers in between are up to you — for example, you may want to test the whole frontend as an integrated system but without hooking it up to the real backend, or vice-versa. Or you may want to have most of your end-to-end tests not interact with your real third-party services. Those sorts of variations can help you manage the trade-off between confidence versus speed and reliability — just be sure to fit your test categories into a pyramid framework so you know which layer is which, how many of each kind of test you should have, and what functionality should be tested in which test category.
Going back to my GraphQL project from earlier, that was tested through three different levels. Unit tests formed the foundation, thoroughly verifying the engine’s edge cases using a fake schema. Additional unit tests validated the behavior of the fields in the real schema. The unit tests were quick to write and quick to run. Integration tests, comprising only a few tests, focused on verifying that the real schema was properly hooked up to the engine, and that queries to the endpoint would work. Then at the top level, end-to-end tests covered user flows in the frontend. These took the longest to run and write, but verified that the frontend was able to use the endpoint correctly for its actual use cases, and ultimately that users were able to use the app properly.
I think this was a pretty good model. In my next project I’m planning to follow a similar structure, but with one more layer above end-to-end tests, for “production fitness” tests 3. These are tests that I want to run in the actual production environment, whose purpose is to verify that all the systems are up and working properly with each other, and that there are no issues with configuration, external integrations, or things like that. These would sit one layer above end-to-end tests on the pyramid, since they build upon those tests — end-to-end tests test the code, while production fitness tests test the whole environment. Since it’s one layer up, there should be fewer of them and they should run slightly less frequently. I plan to just take a subset of the end-to-end tests to use for this purpose, so we won’t even need to write new tests for it.
Adding Tests to Untested Code
In general, the best way to ensure your code is well-tested is to just make sure that, from the beginning, you add and update tests with every change you make. Maintaining that discipline adds a bit of overhead to each change, but it ensures that every part of the code is well tested at all times. As the system gets bigger, that assurance is extremely valuable, and quickly makes up for the initial costs.
But most of us don’t have the luxury of being able to start a project from scratch — most of us are working on existing codebases, and it’s rare for those to have been built with testing in mind from the beginning. We can’t go back and change the past; but we can work to make up for it by going back to old code and retroactively adding the tests we wish were there in the first place.
The first thing an organization needs to do, if it wants to transition to a codebase with higher-quality tests, is to start being more disciplined with all new code changes. Adding a rule that tests need to be written or updated any time code functionality changes will stem the bleeding. Without such a practice, the amount of untested code will keep growing as new changes are made.
The next thing to do, then, is to come up with a plan for how to tackle the existing untested code. If the project has been around for more than a year or two, the amount of work will seem quite daunting. But it’s very achievable if you tackle it gradually and prioritize intelligently. You can probably get 90% of the benefits of testing by just focusing on the most important 10% of your code.
The places that should get tests sooner are those that are updated most frequently. Because the benefits of tests come when the code is updated, tests for these areas pay for themselves faster. There are two approaches you can take to make sure those are the places you’re adding tests to first.
First, you can adopt a “safety net” principle, which says that developers should not change the functionality of any area of code until that area is well tested. Just like a stunt performer should refuse to perform without a safety net, it is responsible to refuse to work on an area of code that isn’t tested. When stakeholders want a particular change made, if that requires working in an untested area of code, they should be told, “the first step will need to be writing tests for the existing functionality,” and that should be incorporated into any time estimates. Because these tests are added based on the work that actually comes up, areas of code that need to be updated more frequently will naturally tend to be addressed quicker than more stable areas.
The second approach is to deal with the inevitable fact that people are unlikely to stick to this principle perfectly, especially when there is pressure from urgent issues. To account for that, it can help to have designated periods of time, such as “tech debt days,” to tackle the backlog of tests that need to be written. That backlog needs to be prioritized explicitly, based on the most frequently changed areas of code. The developers may have a general sense for some of those areas, but there are also tools available that can give you specific data based on the commits in the codebase4. By finding which files or functions lack test coverage, which are changed most often, and which are implicated most often in bugs, you have objective measures that help both with prioritization and with communicating why this work is important. 5
Conclusion
When tests pull their weight, they make software much easier and much safer to work with. When your tests focus on the functionality that you actually care about, and test stable abstractions rather than unstable implementation details, they are more useful and don’t need to be updated as often. Following a testing pyramid helps you manage the tradeoffs of different kinds of tests, so that you have the maximum amount of confidence with the minimum maintenance load. Focusing on the most frequently changed areas of code allows you to get the greatest benefits as soon as possible.
Good tests not only lead to fewer bugs and regressions, but also boost developer confidence and accelerate the development process. When you focus on keeping your tests high-quality, their initial costs are quickly offset by long-term advantages of reduced maintenance efforts and improved software stability.
See this Stack Overflow blog post for other thoughts on why and how to avoid mocks.↩
This idea is based on one of the quadrants discussed in this talk from about 44:15 to 45:10, which discusses a distinction between experimental and strategic systems. This talk is about refactoring, and what are the most important things to architect well, but I believe a similar strategy can be applied to testing, and what are the most important things to test well.↩
This idea is somewhat inspired by this same talk from about 18:25 to 20:55, where the speaker defined a kind of “fitness function” that caught issues in the system, which couldn’t be caught by testing the code alone.↩
CodeScene is one such tool. I will admit I haven’t used it, and it does cost money, but the data it generates seems very useful. But if you don’t want to pay, I imagine you could get a general overview by hacking together an analysis of your git history manually.↩
Idea taken from this talk, from about 28:35 to 34:55. This discusses how to analyze code to prioritize which areas are most important to refactor. The same approach can be taken for which areas are most useful to test.↩